TorchScript란?
TorchScript is a way to create serializable and optimizable models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
TorchScript — PyTorch 1.8.1 documentation
TorchScript TorchScript is a way to create serializable and optimizable models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency. We provide tools to incrementally tran
pytorch.org
torchscript란 공식 문서에서 나왔듯이, PyTorch 코드의 모델을 직렬화하고 최적화하기 위해 사용된다. 또한 이를 이용하면 C++에서도 PyTorch 모델을 사용할 수 있다.
net = build_model()
jit_net = torch.jit.script(net)
print(jit_net.code)
print(jit_net.graph)
사용법은 브매우 간단하다. 모델을 만들고 torch.jit.scipt로 감싸면 된다. 위 코드의 실행 결과는 아래와 같다.
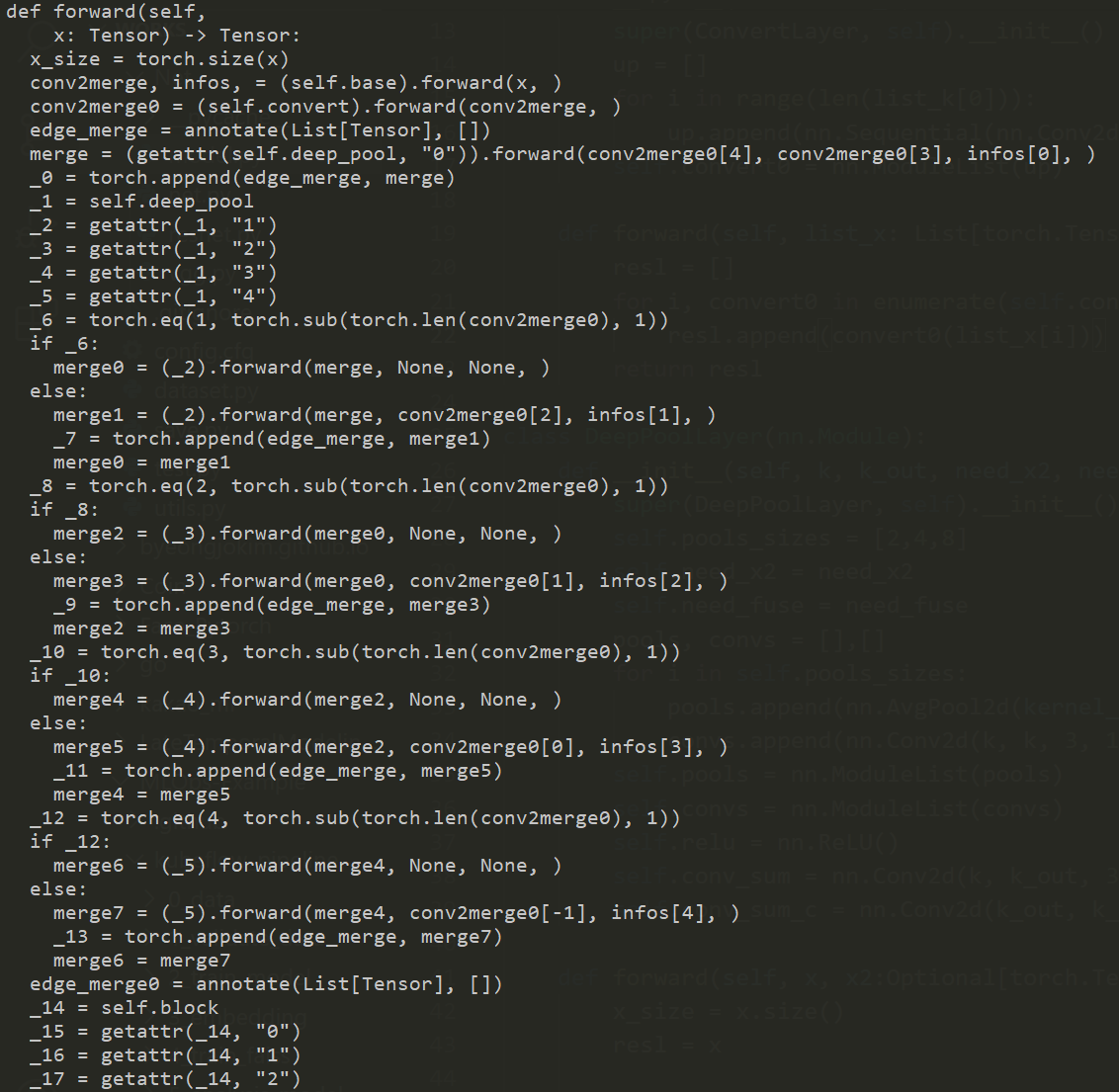
def forward(self,
x: Tensor) -> Tensor:
x_size = torch.size(x)
conv2merge, infos, = (self.base).forward(x, )
conv2merge0 = (self.convert).forward(conv2merge, )
edge_merge = annotate(List[Tensor], [])
merge = (getattr(self.deep_pool, "0")).forward(conv2merge0[4], conv2merge0[3], infos[0], )
_0 = torch.append(edge_merge, merge)
_1 = self.deep_pool
_2 = getattr(_1, "1")
_3 = getattr(_1, "2")
_4 = getattr(_1, "3")
_5 = getattr(_1, "4")
_6 = torch.eq(1, torch.sub(torch.len(conv2merge0), 1))
if _6:
merge0 = (_2).forward(merge, None, None, )
else:
merge1 = (_2).forward(merge, conv2merge0[2], infos[1], )
_7 = torch.append(edge_merge, merge1)
merge0 = merge1
(생략)
graph(%self : __torch__.PoolNet,
%x.1 : Tensor):
%323 : int = prim::Constant[value=-1]()
%96 : None = prim::Constant() # model.py:151:45
%i.1 : int = prim::Constant[value=0]() # model.py:145:31
%i.21 : int = prim::Constant[value=4]() # model.py:145:45
%i.16 : int = prim::Constant[value=3]() # model.py:145:60
%i.6 : int = prim::Constant[value=1]() # model.py:150:40
%i.11 : int = prim::Constant[value=2]() # model.py:148:8
%x_size.1 : int[] = aten::size(%x.1) # model.py:139:17
%4 : __torch__.resnet.ResNet_locate = prim::GetAttr[name="base"](%self)
%6 : (Tensor[], Tensor[]) = prim::CallMethod[name="forward"](%4, %x.1) # model.py:140:28
%conv2merge.1 : Tensor[], %infos.1 : Tensor[] = prim::TupleUnpack(%6)
%9 : __torch__.ConvertLayer = prim::GetAttr[name="convert"](%self)
%conv2merge.3 : Tensor[] = prim::CallMethod[name="forward"](%9, %conv2merge.1) # model.py:141:21
%edge_merge.1 : Tensor[] = prim::ListConstruct()
(생략)
이렇게 감싸진 모델은 기존 모델과 완벽히 동일한 연산을 하게된다. 또한 위 출력을 보면, code attribute에 모델 관련 모든 코드가 저장되어있다. 따라서 torch.jit.script로 감싼 모델 그대로 저장하면 코드파일 없이 모델을 사용할 수 있게된다. 아래는 torch.jit.script로 감싼 모델의 save와 load 하는 간단한 예제이다.
#save.py
jit_net = torch.jit.script(net)
torch.jit.save(
jit_net,
os.path.join(config.result_dir, config.jit_model)
)#load.py
jit_net = torch.jit.load(
os.path.join(config.result_dir, config.jit_model)
)
이전 MLOps 프로젝트에서도 파이프라인 속 독립적인 step에서 코드 복붙을 하기 싫어서 사용한 적이 있다. 이렇게 저장된 모델은 torchserve에서 코드파일 없이 바로 배포가 가능하다.
[Toy] Serving TorchServe in kubeflow pipelines - 1
이 포스팅에는 위의 CD 단계 중 torch-model-archiver에 관련된 내용을 담고 있다. 이전 포스팅에서 언급한 것 처럼, 버전 문제로 KFServing 대신 TorchServe Github를 사용하였다. TorchServe는 pytorch로..
byeongjo-kim.tistory.com
하지만 실제 딥러닝 개발할 때 github에서 clone한 모델을 그대로 torch.jit.script로 감싸면 여러 에러에 마주치게된다. 에러가 생기는 이유를 추측하자면... torch 코드 없기 때문에, 추후 생길 수 있는 불분명한 것들(type, indexing 등)에 대한 에러를 방지하는 것 같다..
ERROR!
아래 예시들은 오픈소스 코드에 torch.jit.script를 사용하면서 겪은 에러들이다. 각 해결방법이 최선은 아닐 것이다.. 하지만 제대로된 reference를 발견하지 못했기 때문에.. 임시방편으로 쓰면 좋을 것 같다.
not annotated with an explicit type

x2와 x3에 Tensor 혹은 None이 들어올 수 있어서 생기는 에러이다. TorchScript가 지원하는 타입은 다음 문서에 적혀있다. 이중 하나를 typing 해야한다.
TorchScript Language Reference — PyTorch 1.8.1 documentation
TorchScript is a statically typed subset of Python that can either be written directly (using the @torch.jit.script decorator) or generated automatically from Python code via tracing. When using tracing, code is automatically converted into this subset of
pytorch.org
x2와 x3는 Tensor 또는 None이 들어올 수 있기 때문에 Optional[ ] 타입을 사용하였고, python의 typing 모듈을 통해 이를 해결하였다.
from typing import Optional
import torch
# ...
def forward(self, x, x2:Optional[torch.Tensor], x3:Optional[torch.Tensor]):
# ...
if self.need_x2 and self.need_x3:
assert x2 is not None
assert x3 is not None
# ...
또한 실제 x2와 x3가 사용되는 분기문(x2와 x3가 None이 아니면 실행)에 assert 문을 사용해서 어떠한 에러가 발생하지 않도록 미리 조치를 해야 torch.jit.script를 감쌀때 에러가 생기지 않는다.
ModuleList/Sequential Indexing is only supported with integer literals.

PyTorch 로 개발할때 매우 편리한 ModuleList와 Sequential에 주의 해야한다. 주로 ModuleList는 아래와 같이 사용된다.
self.convs = nn.ModuleList(convs)
def forward(self, x_list):
result = []
for i in range(len(self.convs)):
result.append(self.convs[i](x_list[i]))
입력이 List[Tensor] (코드의 x_list)로 들어오고, 각 element (코드의 x_list[i])를 각 layer (코드의 self.convs[i])의 입력으로 사용하는 예시이다. 하지만 위 에러를 보면 알 수 있듯이 torch.jit.script를 사용하기 위해서는, i 와 같은 변수로 indexing을 하면 에러가 난다. 즉 0, 1, 2 와 같은 integer을 사용하거나 self.convs를 for 문의 iterator로 직접 사용해야한다. 아래 코드는 self.convs를 iterator를 사용하여 에러를 해결하는 예시이다.
self.convs = nn.ModuleList(convs)
def forward(self, x_list):
result = []
for i, convs in enumerate(self.convs):
result.append(convs(x_list[i]))no attribute

def __init__(self, ...):
if self.condition:
self.conv = nn.Conv2d(...)
def forward(self, ...):
if self.condition:
self.conv(x)
주로 layer의 위치에 따라 다른 모델을 만들 때가 있다. 위의 코드를 보면, 특정 condition이 True 일 때만 self.conv를 선언 하고, 추후 이 self.conv를 사용하는 예시이다. 일반적인 Torch Code로써 잘 작동하는 코드였다. 하지만 torch.jit.script를 사용하면 사용하든 안하든 모든 layer가 graph와 code 상에 올라가기 때문에 사용할 수 있는 모든 것들에 대해 미리 선언을 해놓아야한다. 위 에러는 이와 같이 self.conv_sum_c layer가 if 조건에 의해 선언되지 않았을 때 생겼다. 이는 임시방편으로 선언을 함으로 해결하였다.
def __init__(self, ...):
self.conv = nn.Conv2d(...)
def forward(self, ...):
if self.condition:
self.conv(x)
그리고 위와 같이 에러를 해결하였으면, 학습된 weight을 불러올 때 strict=False로 missing key를 무시해야한다.
net.load_state_dict(torch.load(config.load), strict=False)
더 clean한 코드를 위해서는.. 특정 레이어를 위한 module을 따로 짜는 것이 더 좋지 않을까..? 하지만 이미 학습된 weight이 존재 할 경우.. weight의 이름을 수정해줘야 한다...
does not have a statically determinable length

list_x와 self.convert0은 분명 동일한 길이를 가진 list이다. 하지만 torch.jit.script은 용납하지 못하는 모양이다. 이는 위 ModuleList/Sequential Indexing 에서 소개한 enumerate 쓰는 방법으로 해결할 수 있었다.
Results

이번에 torch.jit.script를 사용하는 프로젝트를 간단히 설명하자면, 기사의 원본 이미지 속 썸네일 영역을 추천하는 프로젝트이다. 위는 기사 속 원본 이미지이다.


위는 torch code로 생성한 썸네일 이미지, 아래는 torch.jit.script로 저장된 모델을 사용한(코드파일 없이) 썸네일 결과이다. 두 결과가 완벽하게 일치하는 것을 알 수 있다.
Review
이렇게 에러들을 하나씩 고치다보니 torch.jit.script으로 모델이 생성되었고, 코드 파일 없이 모델을 불러올 수 있었다. 그냥 전체 모델을 새로 짤까도 생각했었지만, 에러들을 해결하고 싶은 마음에 하나씩 해결하다보니 성공을 하게 되었다.. 하지만 clean한 코드를 위해 그냥 다시 코드를 개발할 계획이다..
'MLOps' 카테고리의 다른 글
| Kubernetes에 EFK 설치 및 튜토리얼 (0) | 2021.05.27 |
|---|---|
| Deep Learning GPU 성능 최적화 전략 (0) | 2021.05.16 |
| [PyTorch] .detach().cpu().numpy()와 .cpu().data.numpy() ? (0) | 2021.04.28 |
| NVIDIA APEX가 빠른 이유 (ft. FP16 vs FP32) (0) | 2021.04.22 |
| Kubeflow - Pipelines 소개 - 2 (0) | 2021.02.24 |



